Speech to text models have improved immensely in the past decade.
What is great is that you have the ability to run them locally.
In this short tutorial I will show you how to use the whisper library with streamlit.
At first we will have to install a few new python packages. Make sure you run:
`pip install whisper streamlit streamlit-audiorec`
To use whisper make sure you have `ffmpeg` installed. Please check whisper docs here.
Now with those packages installed we can jump into code which is actually quite simple.
Create a file called `whisper_example.py` and paste the code below:
import whisper
import torch
import streamlit as st
from st_audiorec import st_audiorec
# This creates the recording widget
wav_audio_data = st_audiorec()
# After we stop the recording we will have some audio/WAV data available
if wav_audio_data is not None:
# This allows us to listen to the recording using the built in streamlit widget
st.audio(wav_audio_data, format="audio/wav")
# The easiest way to load the data into whisper in the correct format
# is to just store them in a temporary file.
with open("/tmp/audio.wav", "wb") as f:
f.write(wav_audio_data)
# Whisper can deal with all the problems around processing wav files adequately.
# On the plus side this is actually quite fast since when loading from a file we can use torch directly to convert
data = whisper.load_audio("/tmp/audio.wav")
# We can load one of the models here, the base model requires fewest amount of memory
model = whisper.load_model("base")
# This is the high level way of transcribing your audio into text.
result = model.transcribe(data)
# Result is a dictionary containing "text" and "segments" and "language"
st.write(result["text"])
# There is also a lower level way that allows you to tweak your audio sample
audio = whisper.pad_or_trim(torch.from_numpy(data).float())
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
# This allows us to check for other potential candidates,
# for example if we want to do some debugging or calculating some metrics
st.write(f"Detected language: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
st.write(result.text)
When you run the code above using `streamlit run whisper_example.py` you should notice an app that looks like this:
Make sure you have your microphone enabled and ensure you have allowed the app within the browser to access your microphone.
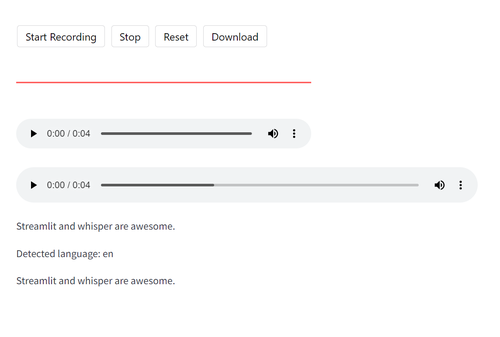
After you record your message it will automatically try to transcribe it.
Below you can see an example of what it printed after I spoke "Streamlit and whisper are awesome".
You can easily expand the code example above by adding langchain and using OpenAI's GPT models to create for example applications that allow you to perform semantic search using internal knowledge bases through speech only, or improve your notes by filling in the parts you have missed. How cool is that?